Download the GNU Unifont Sources and Utilities
GNU Unifont is part of the GNU Project. You can download the latest GNU Unifont source code and utilities here:
- unifont-17.0.05.tar.gz Gzipped Unix Tarball (41 MB download; 132 MB untarred; ~600 MB when built with font files)
- unifont-17.0.05.tar.gz.sig Cryptographic signature with my GPG Public Key
Program Documentation
The following are online documents for Unifont utility programs.
The last two links were generated by Doxygen.
Discussion
The version number is taken from the first two numbers of the Unicode Standard release (major and minor version) and the Unifont release number of this Unicode version.
You can also download the latest release directly from the GNU FTP Mirror (which will automatically redirect to a mirror site), or from the Unifont directory at the GNU Project's FTP site.
Also look at the GNU Project Unifont Page on Savannah.
See the ChangeLog file in the main source directory in the tarball for a detailed list of changes from the previous versions. Some notable changes are listed below:
- Unifont 17.0.04 reorganized font/Makefile to be more efficient for parallel building. You can see a dependency graph of font/Makefile (created with makefile-graph) here: unifont-font-Makefile-graph.svg.
-
Unifont 15.1.01: New Hangul Johab 6/3/1 encoding, with
a Hangul function file and three utility programs. The function
file is
unihangul-support.c. The three new programs are: a)unijohab2htmlto examine letter juxtaposition and overlaps in a syllable as a web page, b)unigen-hangulto combine any full-width Hangul jamo (including Hangul Jamo Extended-A and Extended-B letters) into syllables, and c)johab2syllablesto form modern Hangul syllables with less capability thanunigen-hangul, as a demonstration of other functions inunihangul-support.c. The functions inunihangul-support.csupport syllable formation with all Unicode Hangul letters, including ancient letters. Those functions, along withhangul.h, can also be used by user-created programs for rendering Hangul syllables. -
Unifont 15.1.01:
unihexposeprogram to transpose Unifont glyphs for sending to graphics displays with controller chips designed to autoincrement across a screen by showing 8 pixels in a column at a time. - Unifont 15.0.06: The last release to build TrueType fonts by default. Future versions will just build their OpenType equivalents by default. To manually build TrueType font files, use the command "make truetype" in the "font" directory.
- Unifont 15.0.02: Added Doxygen documentation in html and PDF formats.
- Unifont 14.0.03: Added hex2otf program, contributed by 何志翔 (He Zhixiang). This program can convert Unifont .hex format glyphs into OpenType fonts, TrueType fonts, and more. See the documentation included in the Unifont tarball for a complete description of its capabilities.
- Unifont 14.0.03: Updated unibmp2hex program to support 24-bit RGB .bmp files. 32-bit RGB + alpha channel format files were already supported.
- Unifont 12.1.02: Changed unibmp2hex to convert a file in the RGB color space to monochrome before conversion of the graphical image into a .hex file.
- Unifont 12.1.01: Changed some C function calls to use more hardened alternates.
-
Unifont 12.0.01: Added two new programs:
- unibmpbump, by Paul Hardy, to shift glyphs that were created with unihex2png and later saved as Microsoft Bitmap (.bmp) monochrome files. This allows unibmp2hex to process the resulting image files.
- unihexrotate, by David Corbett, to rotate glyphs in Unifont .hex format clockwise or counterclockwise by a desired number of quarter turns.
- Unifont 6.3: Paul Hardy and Andrew Miller modified Unifont utility programs and shell scripts to extend Unifont beyond the Basic Multilingual Plane.
bdf2psf Source
The Unifont source package creates a PSF 1 font for use on Unix or GNU/Linux systems in console mode. This contains a 512-glyph subset of the Unifont glyphs and is designed to support Ken Iverson's computer language APL (A Programming Language). Not all systems have the bdf2psf Perl script that makes this conversion from a BDF font to a PSF 1 font. If your operating system distribution does not contain that script, you can download a version from /pub/bdf2psf.
Building from the Sources
To build the entire Unifont package from sources, you'll need the following additional software:
- C compiler, the "make" utility, and other standard programs that should come with any GNU/Linux or similar system
- Perl
- bdf2pcf (to create a PCF font from the BDF font)
- FontForge (to build the TrueType font); you can download this at http://fontforge.github.io/en-US/ if your OS distribution doesn't have it
- A graphics program such as GIMP to view generated graphics files
To build everything including the fonts from the source tarball, type:
make BUILDFONT=1
make precompiled
Just typing "make" will build the programs but not the font; if you do not run "make BUILDFONT=1", do not run "make precompiled". When done, you can optionally type "make distclean". That will leave the precompiled directory intact.
Porting Is Such Sweet Sorrow
The Unifont source package is built using GNU tools, including the GNU version of the "make" utility. If you are trying to port Unifont to a new platform, your life will be made much easier using GNU make, awk, sed, gcc, etc. Best of luck to you!
Rebecca Bettencourt's Font Utilities
Rebecca Bettencourt has written two free software programs that are especially well-suited to drawing Unifont glyphs. Her programs are not part of the Unifont package, and so are briefly described here. These are linked on her Kreative Korp website at https://www.kreativekorp.com/software/:

|
Bits'n'Picas — This program can directly read, modify, and save glyphs in Unifont .hex format. |

|
PowerPaint — This program can edit .bmp or .png graphics files created by unihex2bmp and unihex2png (respectively), which are part of the Unicode package. In the Unifont 14.0.03 release, unibmp2hex was updated to support the 24-bit RGB .bmp files that PowerPaint saves. The .png files that PowerPaint saves have always been supported by unipng2hex. |
These programs written by Rebecca can be incorporated into the workflow described in the Drawing Example section below, which provides an example of drawing glyphs using the original Unifont utilities.
UniCucumber, by SkyEye_FAST (aka SkyE) / Masertwer
SkyEye-FAST has written UniCucumber, a web-based drawing
utility for GNU Unifont glyphs, now supporting light and dark
modes. Unifont-style ".hex" files can be imported
and exported, and graphical glyph images can be exported.
UniCucumber is released under GPL 3.0.
![]() Top row buttons have selections for settings, glyph upload and
download, light/dark mode toggle, and a link to the project
source on GitHub.
Top row buttons have selections for settings, glyph upload and
download, light/dark mode toggle, and a link to the project
source on GitHub.
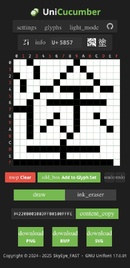
|

|
The settings button pops up a window with selections for mouse click draw modes, glyph width of 8 or 16 pixels (with a height of 16 pixels), glyph preview font selection, and other settings.
The glyphs button toggles a frame allowing Unfont-style
"
The Zi button appears for CJK code points and
links to the The info button will toggle a box with numeric encodings in multiple encoding schemes: ASCII (if applicable), UTF-8, UTF-16, UTF-32, NCR, GBK, GB18030, Big5, Shift-JIS, and EUC-KR. The PNG, BMP, and SVG buttons save graphical glyph output in their respective formats. |
|
UniCucumber is a purely front-end web application, and so can be used offline after a single load. See: |
||
Drawing Example
Here are the general steps I have followed to draw thousands of glyphs for Unifont:
- Run
unihex2bmpto create a bitmap file for editing. - Draw a template grid for a glyph that needs to be drawn.
- Copy this template grid to all glyphs that need to be drawn.
- Draw the glyphs within the grids.
- Erase any part of the grid borders that would otherwise be added
to the final
.hexfile. - Run
unibmp2hexto convert the result to a.hexfile. - Run
unihex2bmpto convert the resulting.hexfile back into a graphics file for final proofing.
0. Optional: Before you begin adding template grids for missing glyphs,
you might want to run unihexgen to create glyphs for code points
that are not yet assigned, or merge the files font/hexsrc/unassigned.hex
with the base glyph file. The simplest way to accomplish this is by starting with
the file font/precompiled/unifont-version.hex.
The unihexgen utility generates a
four-digit hexadecimal code point in the Basic Multilingual Plane, or a
six-digit hexadecimal code point in higher planes. You could generate an entire
set of 256 glyphs and erase the locations that have assigned code points, or
edit them out of the .hex file. When working zoomed in on a
glyph bitmap, having glyphs for the unassigned code points can provide a quick
check that you haven't skipped over any glyphs, or accidentally drawn glyphs
in locations that are not yet assigned.
Below is an example showing the glyphs in the range U+0300 – U+03FF.
Unassigned code points in the Greek and Coptic script range as of Unicode 6.3
are shown as white four-digit hexadecimal numbers on a black background.
The unihexgen utility created those glyphs:
As The Unicode Consortium adds newly-defined code points, the corresponding glyphs
should be removed from font/hexsrc/unassigned.hex. With fewer than
2500 unassigned code points remaining in the Basic Multilingual Plane, this will
not be a substantial task in the future.
The following example demonstrates these steps in drawing glyphs in the range U+00A0 – U+00FF. This example is artificial in a couple of ways. First, those glyphs are already part of Unifont and so don't need to be drawn. Second, if I were going to draw a Latin letter with an accent, I would start by copying the Latin letter that doesn't have an accent, then add the accent at the new location. Apart from that, this shows the general steps I've followed.
1. Run unihex2bmp to create a bitmap file for editing.
This example edits "page" 0, covering the range U+0000 – U+00FF. The command is:
unihex2bmp -p00 < unifont.hex > uni00.bmpThe resulting file is shown below (assuming that the glyphs in the upper half have not yet been drawn):
2. Draw a template grid for a glyph that needs to be drawn. The grid shows the top, left, right, and bottom borders of the drawing area for a glyph. I want the glyphs to be single-width, so I've drawn a vertical line along the 9th pixel; single-width glyphs must end before this vertical line. This is a Latin script, so I've also drawn guidelines on the left side for the baseline, x-height (height of the letter "x"), and cap-height (height of a capital letter).
3. Copy this template grid to all glyphs that need to be drawn.
4. Draw the glyphs within the grids.
Note how the letters line up with the left-hand horizontal marks for the
baseline, x-height, and cap-height. In reality, I would copy over unaccented
versions of letters from the left-hand side of this graphic to the appropriate
locations on the right-hand side, then add the accents. Even in this case though
it is useful to draw a grid line for the top glyph border, so you don't accidentally
draw outside of its boundary (which would result in part of your addition getting
chopped off when converted back into .hex format).
Note that U+00AD, Soft Hyphen, is a special formatting character and so isn't
drawn in this example. Such a formatting character would be added to
font/hexsrc/nonprinting.hex if it were to have any visual representation.
As an example, U+00AD was copied from U+002D after the grid template was copied in all upper cells. U+00AD is a soft hyphen, and we want to denote that it will have the same shape as the hyphen, U+002D. We could do the same thing with letters that are similar.
5. Erase any part of the grid borders that would otherwise be added
to the final .hex file.
This requires that the vertical line along the 9th pixel be erased.
Note that the grid marks that are outside the 16-by-16 pixel glyphs area
can remain; unibmp2hex will ignore them as they are not inside
the glyph area.
6. Run unibmp2hex to convert the result to a
.hex file.
The command for this is:
unibmp2hex < uni00.bmp > uni00.hexThe hex file isn't shown, but you can look at it here.
7. Run unihex2bmp to convert the resulting .hex
file back into a graphics file for final proofing.
This is a double-check to make sure no part of a grid line was accidentally
converted into the .hex file. The end result looks good, so
we can use the new .hex file.
If you draw glyphs that should be moved to font/hexsrc/nonprinting.hex,
remember to move them from the .hex file you've just created into
nonprinting.hex before merging the main results with
unifont-base.hex. In the example above, U+00AD is a special character,
a soft hyphen that only prints if a text editor breaks a word at that location.
If a text editor does choose to break a word at that location, a hyphen (U+002D)
is printed. This glyph is saved in nonprinting.hex rather than
unifont-base.hex.
Also remove any glyphs for unassigned code points from your new .hex
file, because those unassigned glyphs are already in
font/hexsrc/unassigned.hex. The easiest way to accomplish this is
to erase the four-digit hexadecimal glyphs from the bitmap file before converting
it back into a .hex file.
As a simple check against duplicates, in font/hexsrc type this command:
wc -l *.hexThe total number of lines in all these files should be 63,488. Also run the following command from the same directory as a further check against duplicates:
sort *.hex | unidup
If unidup doesn't complain that there are duplicate code points,
and if the total number of glyphs in .hex files is 63,488,
chances are the .hex files are in good shape. Congratulations!
I Wonder as I Wander
GNU Unifont covers the Unicode Basic Multilingual Plane (BMP). When I first looked at it in late 2007, GNU Unifont was missing roughly 17,500 glyphs from the Unicode 5.0 Basic Multilingual Plane (BMP). Since then, the addition of Qianqian Fang's Unibit CJK glyphs and my additions have provided complete coverage of the Unicode 5.1 BMP, including the over 1,000 glyphs added in Unicode 5.1 to the BMP. See the Unifont Glyphs page for more details on the font's latest status.
I was on travel, and didn't have access to a GNU/Linux system but wanted to work with Unifont. I did have the Cygwin package installed on my Windows laptop but alas, did not have Perl installed to use the Unifont creator's Perl scripts. What to do?
They say that when all you have is a hammer, everything looks like a nail. Well, all I had was a C compiler!
Necessity is the mother of invention, so I decided to write a C version of the Perl script that converts .hex files into ASCII and back for easy font editing in a text editor. I do not include that software for download here, because what I did next was far better.
I completed that software in short order, but then realized that if the glyphs were represented as bitmaps, they could be edited in a graphics editor. As a result, characters could be edited and viewed with the same aspect ratio that they'd have on final display. What better way to edit them than at the correct aspect ratio from the beginning?
The resulting software displays a full 32-bit Unicode value (leading zeroes and all) to be displayed on a page, even though Unifont at the time only supported Plane 0, the BMP, and even though Unicode itself only specifies values up to U+10FFFF. The upper two byte values are printed in the upper left-hand corner, as "U+nnnn". Characters on a page are arranged in a 16 by 16 grid (256 characters per page). Notches in the grid denote vertical and horizontal centers, and vertical and horizontal boundaries for 8 pixel wide and 16 pixel wide characters.
For example, the distance from the left-most notch in a grid square to the right-most notch in a grid square is 16 pixels, and the distance from the top-most notch in a grid square to the bottom-most notch in a grid square is also 16 pixels. The grid lines themselves are on a 32 by 32 pixel grid, providing some whitespace for clarity. Any graphics editor providing 400 times or 800 times magnification should suffice for easy editing of these bitmaps. I made about half of my pixel edits at 400x magnification, and the other half at 800x magnification.
Samples of unihex2bmp output can be found at the end
of the Unicode Tutorial page on this website.
I began with the Wireless Bitmap file format (.wbmp) because it was the simplest graphics format I could find: a rectangular monochrome bitmap. It doesn't get any simpler than that. Once that was working, I added header processing for the Microsoft Windows Bitmap (.bmp) format. That allows editing in a wider range of graphics editors.
In a Wireless Bitmap file, a white pixel is always represented by a "1" bit, and a black pixel is always represented by a "0" bit. That is also the default Windows Bitmap encoding produced by Microsoft Paint (which I used along with my programs under cygwin), so that is the encoding that I used for pixels: white is a "1" bit, and black is a "0" bit.
Some sample results appear at the bottom of the Unicode Tutorial web page on this site.
After adding that functionality, I decided to add one more option: allowing the matrix to be transposed ("flipped", going from top to bottom, left to right rather than from left to right, top to bottom) to match the glyph ordering in the Unicode standard itself. (Every other system I've seen, including the commercial font editing tools from Font Lab, arrange characters the other way, from left to right, top to bottom). I realized that would allow easy comparison with the Unicode code charts to facilitate adding new glyphs.
The two main utilities,
unihex2bmp and unibmp2hex,
convert GNU Unifont .hex files to and from
Windows Bitmap (.bmp) and Wireless Bitmap (.wbmp) files.
These two utilities use the Windows Bitmap format to
allow glyph editing with the Microsoft Paint accessory bundled with
Windows. I was on the road with my laptop when I wrote them,
and wanted software that would let me easily edit GNU Unifont on
my Windows laptop.
The utilities were written as a quick hack, without tons of robust error checking or other bullet-proofing. This software is written in C, and should compile and run on just about anything that has a C compiler.
Licensing
Various programs in the Unifoundry.com GNU Unifont Utility Package are Copyright Roman Czyborra, Paul Hardy, Luis Alejandro González Miranda, Andrew Miller, David Corbett, and 何 志 翔 (He Zhixiang). Copyright on the enclosed fonts is noted in the ChangeLog file. For more details on the history, see the README file in the tarball.
The Unifoundry.com GNU Unifont Utility Package is free software: you can redistribute it and/or modify it under the terms of the GNU General Public License (GPL) as published by the Free Software Foundation, either version 2 of the License or (at your option) any later version.
Fonts in the package are distributed under the terms of the GNU GPL, either version 2 or (at your option) a later version, with the exception that embedding the fonts in a document does not in itself bind that document to the terms of the GNU GPL.
The Unifoundry.com GNU Unifont Utility Package is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with the Unifoundry.com GNU Unifont Utility Package. If not, see http://www.gnu.org/licenses/.
Utilities
I (Paul Hardy) initially wrote four main utility programs in this package:
unihex2bmp— converts one 256 code point page of a .hex Unifont file into a bitmapped 16 by 16 grid.unibmp2hex— converts one of the above bitmaps back into .hex format.unipagecount— counts the number of code points that have representation in a .hex Unifont file.unidup— searches for duplicate code point entries in a sorted a .hex Unifont file.
Usage
The unihex2bmp and unibmp2hex
programs accept the following options:
-
-i -
Specify the input file. The default is
stdin. For example, "-iunifont.hex" specifies the input file as "unifont.hex". -
-o -
Specify the output file. The default is
stdout. For example, "-omyoutput.bmp" specifies the output file as "output.bmp". Warning: there's no check to see if an output file exists — these utilities will clobber an existing file for output. -
-p -
Specify a "page", or block of 256 code points, to convert.
"Page" is my term, because that's what prints on a bitmap
graphics page; it isn't a standard Unicode term. For example,
-p83specifies the range U+8300 through U+83FF. If you don't specify a page withunibmp2hex, it figures out the page by reading the row and column labels in the bitmap file. The default page is 0.
In addition, unihex2bmp accepts the following options:
-
-w - Create a Wireless Bitmap graphics file instead of the default Windows Bitmap file.
-
-f - "Flip" (transpose) the grid to be the transposed order of the code charts that appear in the Unicode standard. This prints code points left to right, then top to bottom. The default order is top to bottom, then left to right.
Note that unibmp2hex will figure out if a bitmap
is flipped (transposed) or not, and whether it is in Wireless Bitmap
or Microsoft Bitmap format. It reads the last column (or top row if
flipped) of numbers to the
left of the grid as the format for all hex digits, then compares
the other row and column headers to determine the "page", unless the
page is specified with the -p command line option.
unibmp2hex outputs characters in the BMP in standard
Unifont .hex format. If a character is above the BMP, it outputs hex codes
preceded by an eight digit hexadecimal number rather than a four digit
hexadecimal number, with everything else being the same.
unibmp2hex only understands one height, 16 pixels;
it only understands two widths, 8 or 16 pixels (plus an unsupported,
experimental mode for glyphs that are 32 pixels wide). When reading the center
of each 32 by 32 pixel grid, it detects whether or not the second half
of the center 16 by 16 pixel grid is blank. If it is, then it outputs
the .hex character as a 16 row by 8 column hex code. If there is even
one black pixel in the second half of the 16 by 16 grid, it outputs the
.hex character as a 16 row by 16 column hex code.
Caveat Emptor. These programs were written very, very quickly over a few evenings as a hack. It wouldn't surprise me if they have bugs, but they seem to work perfectly. In addition, these programs don't contain much in the way of error checking. If you do feed these programs bogus values or anything similar, expect the unexpected.
GNU Unifont Status
The unipagecount utility prints the high-order
nybble as row headers (in the left-most column) and the low-order nybble
as column headers (in the first row). Values range from 0 for a 256
character area with no entries to 100 (hex) for a 256 character area with
all entries present.
As an historical snapshot, here are the results on the 2008-01-28 unifont.hex file (today the BMP is complete, so arguably unipagecount is no longer needed):
0 1 2 3 4 5 6 7 8 9 A B C D E F
0 100 100 100 100 100 100 100 100 100 100 5F 68 5A 62 100 100
1 B2 53 100 100 100 100 100 3D 65 2B 100 87 100 100 100 100
2 100 DF F2 93 EB EE BC BB 100 0 0 E1 100 100 73 100
3 EC B5 53 64 100 100 100 100 100 100 100 100 100 100 100 100
4 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100
5 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100
6 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100
7 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100
8 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100
9 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100
A 1 0 0 0 3C 100 100 100 9C 100 100 100 100 100 100 100
B 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100
C 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100
D 100 100 100 100 100 100 100 100 0 0 0 0 0 0 0 0
E 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100 100
F 100 100 100 100 100 100 100 100 100 100 89 FF 30 3E E1 C7
You can see that the first ten blocks of 256 characters (U+0000 through U+09FF, in the upper left-hand corner) are complete: all 10016, or 25610 characters have glyphs.
Some 256 character blocks don't have any assignments. The range U+D800 through U+DFFF is reserved for surrogate pairs. The range U+E000 through U+F8FF is reserved for private use.
The Unifont Glyphs page shows a color-coded view of font coverage.
This was made with the unipagecount program with
the -l option, to produce HTML output with links.
Any box that is light green is 100 percent complete. Any box that
is red or near-red has no or hardly any glyphs complete. Yellow
and orange are intermediate, with orange cells having less coverage
than yellow cells.
Combining Characters
The combining character dashed circle in Roman Czyborra's original
unifont.hex file had this pattern:
The program unigencircles will superimpose these
dashed circles over combining characters in the current unifont.hex
file, producing a modified unifont.hex file as output.
You can see this, for example, in the Combining Diacritical Marks block at U+0300 through U+036F.
In the original unifont.hex file, not all combining circles
followed this pattern precisely. For that reason, I wrote
uniunmask for version 1.02. This program reads
a second .hex file,
masks.hex, and XORs it with the main .hex file for
any matching code points. This allows combining circle marks to appear
in a master file, but be easily removed for display, for example on
X-Windows.
Now that the dashed combining circles have been removed from the main hex file,
uniunmask will no longer part of the source code distribution.
GNU Unifont and TrueType
Luis Alejandro González Miranda has created a utility to convert the GNU Unifont into a TrueType font by using fontforge. His website is http://www.lgm.cl/trabajos/unifont/index.en.html, home page at http://www.lgm.cl/.Roman Czyborra's GNU Unifont Utilities
When Roman's website went down in 2008, I assembled a gzipped tar file of
his Perl scripts (bdfimplode.pl, hex2bdf.pl,
hexdraw.pl, and hexmerge.pl) for download.
Here's that tarball from 2008:
Aux Armes, Netizens!
A call to arms, or "Where do I sign up?"
Roman Czyborra had asked that additions be emailed in .hex format to (anti-spam version of address) unifont at his domain czyborra.com. Current news on GNU Unifont was available at http://czyborra.com/unifont/.
You can send any updates to unifoundry at this domain, unifoundry.com, and I'll add them to my master copy for the next release. You can also send a copy to Roman. Thanks!
If you have any questions, please email unifoundry at this domain name (not spelled out because of spammers).
